页面优化-为什么script最好放底部link最好放头部
这里涉及到一个问题,就是页面的渲染阻塞。
css加载不会阻塞DOM树的解析,但会阻塞DOM树渲染并且阻塞后面的js语句的执行。
浏览器在下载JS的时候,会阻止一切其他活动
JS会阻塞所有内容的呈现,而外部JS只会阻塞其后内容的显示CSS
关于CSS,大家肯定都知道的是<link>标签放在头部性能会高一点,少一点人知道如果<script>与<link>同时在头部的话,<script>在上可能会更好。这是为什么呢?下面我们一起来看一下CSS对DOM的影响是什么。
css加载会阻塞DOM树的解析渲染吗?
<!DOCTYPE html>
<html lang="en">
<head>
<title>css阻塞</title>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<style>
h1 {
color: red !important
}
</style>
<script>
function h () {
console.log(document.querySelectorAll('h1'))
}
setTimeout(h, 0)
</script>
<link href="https://cdn.bootcss.com/bootstrap/4.0.0-alpha.6/css/bootstrap.css" rel="stylesheet">
</head>
<body>
<h1>这是红色的</h1>
</body>
</html>假设: css加载会阻塞DOM树解析和渲染
假设结果: 在bootstrap.css还没加载完之前,下面的内容不会被解析渲染,那么我们一开始看到的应该是白屏,h1不会显示出来。并且此时console.log的结果应该是一个空数组。
实际结果:如下图

css会阻塞DOM树解析?
由上图我们可以看到,当css还没加载完成的时候,h1并没有显示,但是此时控制台输出如下

可以得知,此时DOM树至少已经解析完成到了h1那里,而此时css还没加载完成,也就说明,css并不会阻塞DOM树的解析。
css加载会阻塞DOM树渲染?
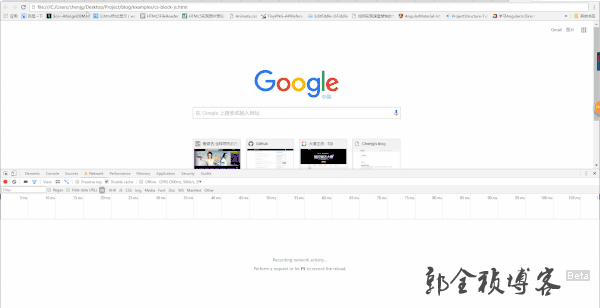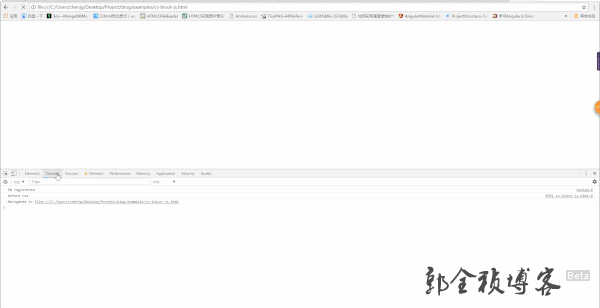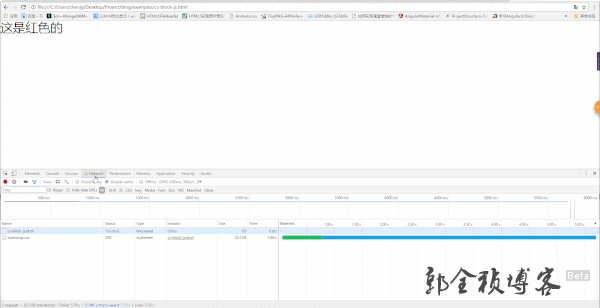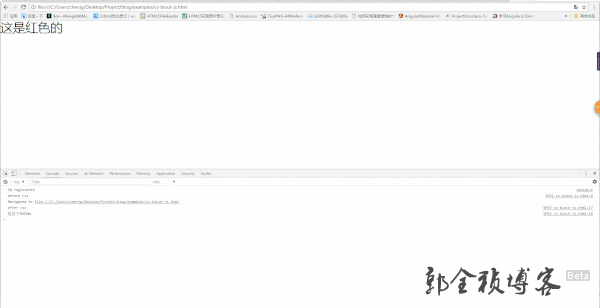
由上图,我们也可以看到,当css还没加载出来的时候,页面显示白屏,直到css加载完成之后,红色字体才显示出来,也就是说,下面的内容虽然解析了,但是并没有被渲染出来。所以,css加载会阻塞DOM树渲染。
浏览器的这个策略其实很明智的,想象一下,如果没有这个策略,页面首先会呈现出一个原始的模样,待CSS下载完之后又突然变了一个模样。用户体验可谓极差,而且渲染是有成本的。
因此,基于性能与用户体验的考虑,浏览器会尽量减少渲染的次数,CSS顺理成章地阻塞页面渲染。
但是
<header>
<link rel="stylesheet" href="/css/sleep3000-common.css">
<script src="/js/logDiv.js"></script>
</header>如果css加载需要很久,就会出现类似CSS阻塞了页面渲染,还阻塞了DOM解析的情况。
刚才已经证明了CSS是不会阻塞的,那么阻塞了页面解析其实是JS!
如果脚本的内容是获取元素的样式,宽高等CSS控制的属性,浏览器是需要计算的,也就是依赖于CSS。浏览器也无法感知脚本内容到底是什么,为避免样式获取,因而只好等前面所有的样式下载完后,再执行JS。
这就是为何<script>与<link>同时在头部的话,<script>在上可能会更好了么?之所以是可能,是因为如果<link>的内容下载更快的话,是没影响的,但反过来的话,JS就要等待了,然而这些等待的时间是完全不必要的。
JS
JS,也就是<script>标签,估计大家都很熟悉了,不就是阻塞DOM解析和渲染么。然而,其中其实还是有一点细节可以考究一下的,我们一起来好好看看。
JS 阻塞 DOM 解析
首先我们需要一个新的JS文件名为blok.js,内容如下:
const arr = [];
for (let i = 0; i < 10000000; i++) {
arr.push(i);
arr.splice(i % 3, i % 7, i % 5);
}
const div = document.querySelector('H1');
console.log(div);
其实那个数组操作时没意义的,只是为了让这个JS文件多花执行时间而已。之后把这个文件插入头部,浏览器跑一下。
浏览器转圈圈一会,这过程中不会有任何东西出现。之后打印出null
现象就足以说明JS 阻塞 DOM 解析了。其实原因也很好理解,浏览器并不知道脚本的内容是什么,如果先行解析下面的DOM,万一脚本内全删了后面的DOM,浏览器就白干活了。更别谈丧心病狂的document.write。浏览器无法预估里面的内容,那就干脆全部停住,等脚本执行完再干活就好了。
对此的优化其实也很显而易见,具体分为两类。如果JS文件体积太大,同时你确定没必要阻塞DOM解析的话,不妨按需要加上defer或者async属性,此时脚本下载的过程中是不会阻塞DOM解析的。
而如果是文件执行时间太长,不妨分拆一下代码,不用立即执行的代码,可以使用一下黑科技:setTimeout()。当然,现代的浏览器很聪明,它会“偷看”之后的DOM内容,碰到如<link>、<script>和<img>等标签时,它会帮助我们先行下载里面的资源,不会傻等到解析到那里时才下载。
浏览器遇到 <script> 标签时,会触发页面渲染
每次碰到<script>标签时,浏览器都会渲染一次页面。这是基于同样的理由,浏览器不知道脚本的内容,因而碰到脚本时,只好先渲染页面,确保脚本能获取到最新的DOM元素信息,尽管脚本可能不需要这些信息。
结论
- css加载不会阻塞DOM树的解析
- css加载会阻塞DOM树的渲染
- css加载会阻塞后面js语句的执行
JS 阻塞 DOM 解析,但浏览器会"偷看"DOM,预先下载相关资源。
浏览器遇到 <script>且没有defer或async属性的 标签时,会触发页面渲染,因而如果前面CSS资源尚未加载完毕时,浏览器会等待它加载完毕在执行脚本。
所以,你现在明白<script>最好放底部,<link>最好放头部,如果头部同时有<script>与<link>的情况下,最好将<script>放在<link>上面
为了避免让用户看到长时间的白屏时间,我们应该尽可能的提高css加载速度,比如可以使用以下几种方法:
- 使用CDN(因为CDN会根据你的网络状况,替你挑选最近的一个具有缓存内容的节点为你提供资源,因此可以减少加载时间)
- 对css进行压缩(可以用很多打包工具,比如webpack,gulp等,也可以通过开启gzip压缩)
- 合理的使用缓存(设置cache-control,expires,以及E-tag都是不错的,不过要注意一个问题,就是文件更新后,你要避免缓存而带来的影响。其中一个解决防范是在文件名字后面加一个版本号)
- 减少http请求数,将多个css文件合并,或者是干脆直接写成内联样式(内联样式的一个缺点就是不能缓存)
- 不要在嵌入的JS中调用运行时间较长的函数,如果一定要用,可以用`setTimeout`来调用
文章参考:
https://juejin.im/post/59c60691518825396f4f71a1
https://www.cnblogs.com/chenjg/p/7126822.html
https://blog.csdn.net/lxsjh/article/details/79158820

